Combating concept drift in LLM applications
Your LLM application works beautifully at launch. The model understands user preferences, accuracy metrics look great, and feedback is positive. Then, gradually—or sometimes suddenly—performance starts to degrade. Users complain. Metrics slide. What happened?
The answer is concept drift: the underlying relationship between inputs and desired outputs changes over time, even when the statistical distribution of inputs looks similar. In traditional ML, we retrain models on new data. But for LLM applications built with prompt engineering (what Andrej Karpathy calls “Software 3.0”) retraining isn’t the first option. We need a different approach.

The Challenge: Real Concept Drift in Production
I built Noteworthy Differences, an LLM-powered system that analyzes Wikipedia page revisions and predicts which changes are noteworthy enough to notify editors. Noteworthiness is inherently subjective; what matters to one person may not matter to another. The system learns from user feedback to align with individual preferences.
To study concept drift systematically, I became the user. Over four time periods in production, I deliberately became more selective about what I considered noteworthy. I used the app’s feedback feature to collect labeled examples, randomly split into training (60%) and test sets (40%). The result: a real-world dataset showing severe concept drift.
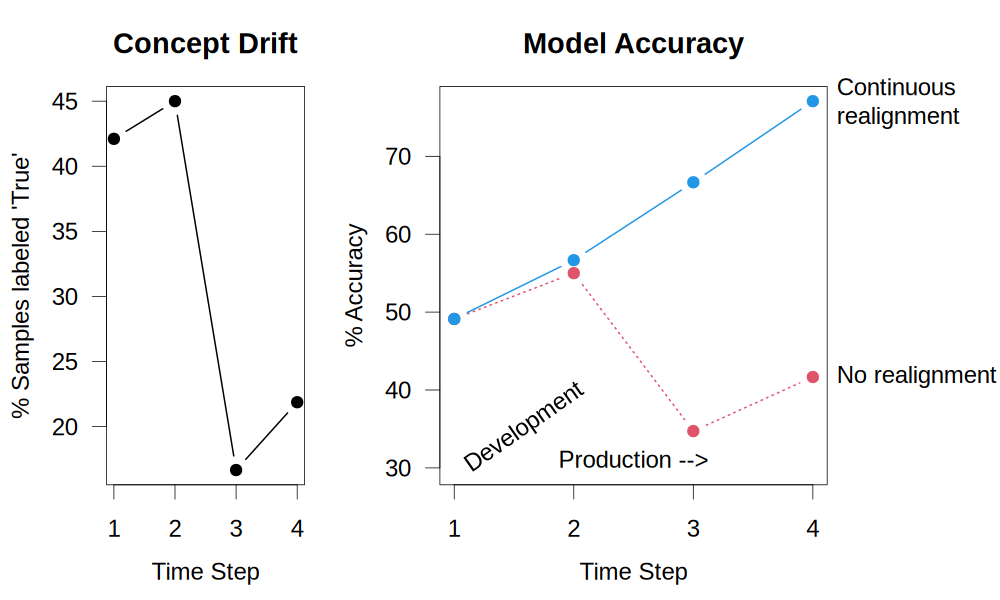
The left panel below tells the story. At time step 1 (development), I labeled 42% of differences as noteworthy. By time step 4, that dropped to just 22%, a 48% decrease in the positive class rate. This is textbook concept drift.
The Architecture: Learning from Hard Examples
The system uses a multi-level architecture:
- Two classifier models (heuristic and few-shot) independently analyze each revision
- An AI judge makes the final decision, with alignment text in its prompt
- Disagreements between classifiers identify hard examples (~9% of cases) that need human review
This architecture serves two purposes: it focuses human attention on truly ambiguous cases, and it provides a confidence score based on the level of agreement among models.
For easier feedback collection the app has a “🎲 Special Random” button that classifies random pages until a hard example is found. Try it out!
The Solution: Continuous Realignment
The alignment text is generated by summarizing user feedback and incorporating it into the AI judge’s prompt. Importantly, both the realignment and evaluations are automated by Python scripts available in the GitHub repository.
During development, the initial alignment achieved 53% accuracy on the test set, a 16-point improvement over the baseline (37%). (These values are quoted from the development cycle documented in the project’s README; averages of multiple repetitions resulted in somewhat lower accuracy for the initial alignment as shown in the plot.)
But what happens during production when preferences change? I tested two strategies:
- No realignment: Use the development alignment throughout production (red line in right panel)
- Continuous realignment: Update the alignment at every time step with accumulated feedback (blue line)
The results are striking. The model with no realignment fluctuates between 35% and 57% accuracy, struggling to adapt to shifting preferences. Only continuous realignment maintains high accuracy, reaching 77% by time step 4, a 35-point improvement over the static model. This 35-point difference represents the cost of ignoring concept drift in production LLM applications.
What I Learned
- Concept drift is measurable and consequential. In this experiment, the positive class rate dropped 48% over time. The static model’s accuracy fluctuated wildly in response.
- Continuous monitoring is essential. Without evaluation harness tracking performance over time, concept drift would have been invisible until users complained.
- One-time alignment isn’t enough. Even a significant improvement during development degrades as user preferences evolve. The system needs to keep learning.
The most important lesson: Prompt engineering can be iterative and data-driven. The realignment process systematically updates prompt instructions through a feedback loop, treating prompts as adaptable components rather than static text.
Implications for LLM Practitioners
In production LLM applications, standing still means falling behind. Iteratively refining prompts with accumulated user feedback isn’t just good practice—it’s the difference between a system that degrades and one that improves with use.
For practitioners building production LLM systems:
- Implement feedback collection from day one
- Build evaluation infrastructure that runs automatically on new data
- Monitor both input distributions and output quality over time
- Plan for prompt engineering as a production process, not a one-time development task
The complete implementation, including evaluation and realignment scripts, is available on GitHub. The live app is deployed on 🤗 Hugging Face Spaces. Feedback data is publicly available in this 🤗 Hugging Face Dataset.
Further Reading
Evidently AI: Concept Drift in ML
AWS: Monitoring Drift in Gen AI Applications
Orq.ai: Model vs Data Drift
Fiddler AI: How to Monitor LLMOps Performance