Where science meets AI innovation
My unique perspective combines rigorous scientific methodology with modern ML engineering practices. I’ve spent over a decade turning complex research questions into elegant software solutions. I’m always on the lookout for opportunities to pursue my passion for building AI and data analysis software that is dependable, adaptable, and impactful.
🔬 Research projects
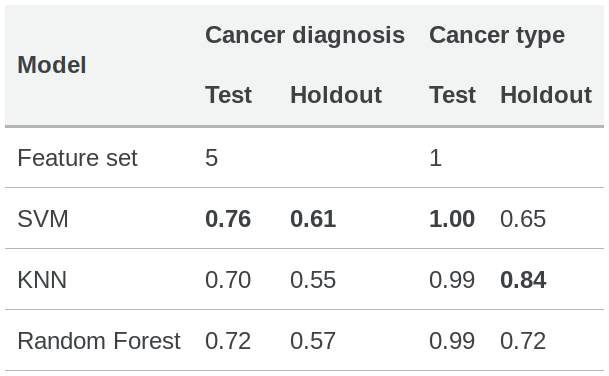
BreCol benchmark
On the importance of holdout studies for assessing cancer classification models
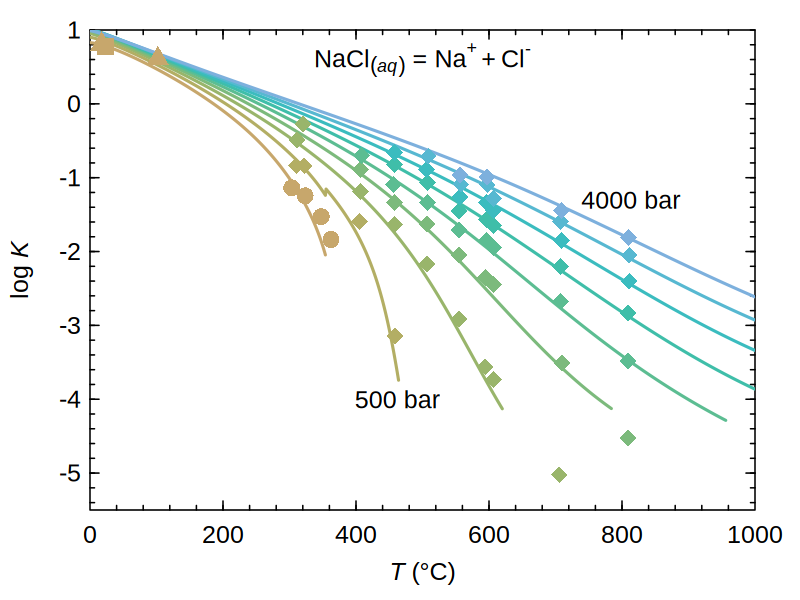
CHNOSZ package
Enabling scientific discovery through thermodynamic calculations and diagrams
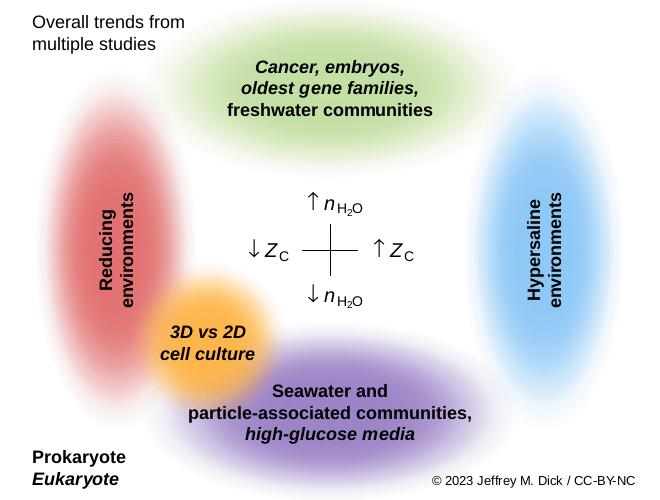
More projects
Understanding geosphere-biosphere coevolution through geochemistry and genomic data analysis
🖥️ AI deployments
Making knowledge accessible through conversational AI
Agentic retrieval for 10+ years of email archives, designed for deep research and continual data updates. Walkthrough video

AI alignment for detecting meaningful changes
This project leverages AI alignment with human-in-the-loop to build a practical solution for filtering signal from noise in document updates.
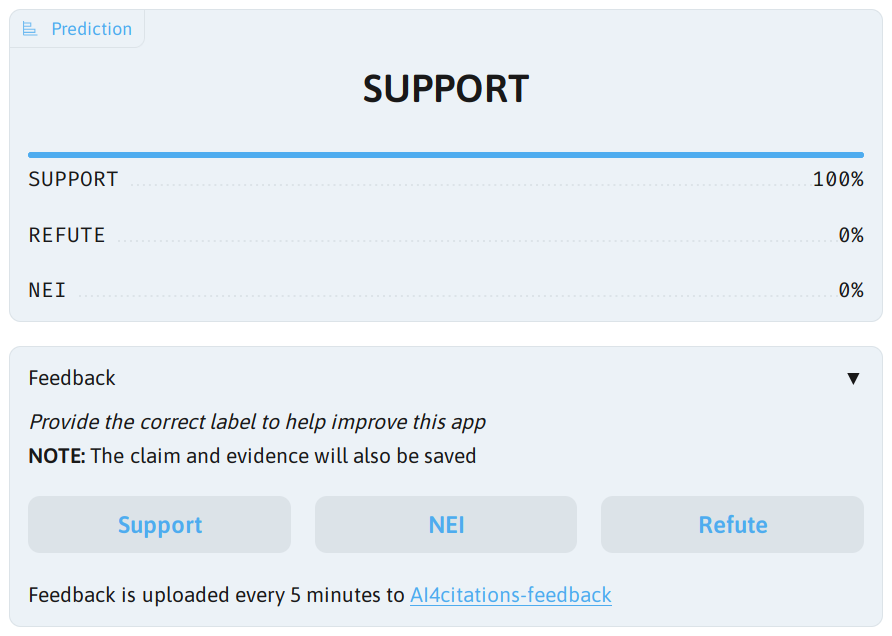
Fighting inaccurate citations with AI
Taking citation verification analysis from research to production through model optimization, deployment, and feedback collection.
📝 Featured blog posts

Combating concept drift in LLM applications
Your LLM application works beautifully at launch. The model understands user preferences, accuracy metrics look great, and feedback is positive. Then, gradually—or sometimes suddenly—performance starts to degrade. Users complain. Metrics slide. What happened?

Modern understanding of overfitting and generalization in machine learning
The conventional wisdom about the bias-variance tradeoff in machine learning has been dramatically challenged by modern neural networks. Traditionally, we believed that increasing model complexity would decrease bias but increase variance. However, recent research reveals that highly overparameterized models often generalize exceptionally well despite perfectly fitting the training data.
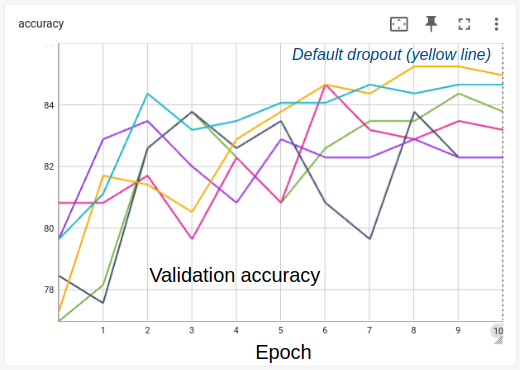
Experimenting with transformer models for citation verification
This article provides a systematic comparison of transformer-based architectures for scientific claim verification, evaluating their performance across multiple datasets and examining the trade-offs between model complexity, computational efficiency, and generalization capabilities.