Deploying AI4citations: From research to production
Building a production-ready citation verification system with automated testing, comprehensive APIs, and scalable deployment
Project Highlights
🚀 Live Production App: AI4citations is deployed on Hugging Face Spaces with GPU acceleration
🔧 Complete ML Pipeline: End-to-end system from data processing (pyvers package) to model deployment with automated CI/CD workflows
🌐 Multi-Modal API Access: Three evidence retrieval methods (BM25S, DeBERTa, OpenAI GPT) accessible via both web interface and programmatic API
System Architecture
┌─────────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ PDF Upload │ │ Text Input │ │ Model Selection│
└─────────┬───────┘ └─────────┬────────┘ └─────────┬───────┘
│ │ │
└──────────────────────┼───────────────────────┘
│
┌────────────▼────────────┐
│ Gradio Interface │
│ (API + Web UI) │
└────────────┬────────────┘
│
┌─────────────────────┼─────────────────────┐
│ │ │
┌────────▼────────┐ ┌────────▼────────┐ ┌───────▼───────┐
│ BM25S Retrieval│ │DeBERTa Retrieval│ │ GPT Retrieval│
└────────┬────────┘ └────────┬────────┘ └───────┬───────┘
│ │ │
└─────────────────────┼────────────────────┘
│
┌────────────▼────────────┐
│ Claim Verification │
│ (Fine-tuned DeBERTa) │
└────────────┬────────────┘
│
┌────────────▼────────────┐
│ Results + Feedback │
│ (Support/Refute/ │
│ Not Enough Info) │
└─────────────────────────┘
Data Pipeline Implementation
The data processing pipeline is implemented through the pyvers package, which provides a robust foundation for claim verification model training and deployment. The pipeline supports multiple data sources including local JSON files and Hugging Face datasets, with consistent label encoding across different natural language inference datasets. The system logs training metrics and validation performance visualization with TensorBoard.
The production model was trained using PyTorch Lightning with cross-dataset shuffling from SciFact and Citation-Integrity datasets (see a previous blog post), achieving a 7 percentage point improvement over single-dataset baselines.
Model deployment leverages Hugging Face’s transformers API for edge device inference and managed hosting with dynamic GPU allocation through ZeroGPU on Hugging Face Spaces. Data flow is optimized for real-time inference with text normalization, PDF processing through PyMuPDF, and efficient tokenization using the transformers library.
API Design and Implementation
The application exposes its functionality through a well-structured API implemented using Gradio, providing both Python and JavaScript client libraries. Gradio’s built-in API features include automatic endpoint generation, parameter validation, and comprehensive documentation.
The API design follows RESTful principles with three primary endpoints: model selection, evidence retrieval, and claim verification. Each endpoint accepts structured parameters with proper type validation and returns consistent response formats. The system supports file uploads for PDF processing and provides detailed confidence scores for all predictions.
Gradio’s API recorder feature allows users to capture their interactions through the web interface and automatically generate corresponding API calls, bridging the gap between manual exploration and programmatic access. The system also supports Model Context Protocol (MCP) integration for tool usage by LLMs. For more information on using Gradio to create AI-accessible tools, see the Hugging Face MCP course.
Testing Infrastructure
Comprehensive testing is implemented using Python’s unittest framework with both unit and integration testing coverage. Unit tests verify individual components like retrieval functionality, while integration tests validate the complete API workflow using the Gradio client library.
The test suite includes automated PDF processing validation, model prediction checks, and API endpoint functionality verification. Integration tests launch the full application in a subprocess and perform end-to-end API calls to ensure production readiness.
Continuous integration is managed through GitHub Actions workflows that execute tests on every commit and pull request. Code coverage reporting is handled by Codecov, providing detailed insights into test coverage across all components and identifying areas requiring additional testing.
API Documentation
The Gradio framework automatically generates comprehensive API documentation accessible within the app. The documentation includes three primary API endpoints:
Model Selection (/select_model): Allows switching between the fine-tuned DeBERTa model and the base model,
accepting a model name parameter and returning the selected configuration.
Evidence Retrieval (/retrieve_evidence): Processes PDF uploads and claim text to extract relevant evidence using BM25S, DeBERTa, or GPT methods,
with configurable top-k sentence selection and token usage tracking.
Claim Verification (/query_model): Takes claim and evidence text as input and returns structured predictions with confidence scores
for Support, Refute, and Not Enough Information categories.
Each endpoint provides complete parameter specifications, return value descriptions, and executable code examples for both Python and JavaScript clients.
Installation and Usage Instructions
The GitHub repository provides comprehensive instructions for local installation and deployment. Users can clone the repository, install dependencies via pip requirements, and launch the application locally using Gradio. The setup supports both CPU and GPU inference with automatic hardware detection.
For production deployment, the application is containerized and deployed on Hugging Face Spaces with GPU acceleration. Environment variables handle API key configuration for OpenAI GPT integration.
The README includes quick start instructions, dependency management, API usage examples, and troubleshooting guidance.
Production Deployment
AI4citations is deployed as a production application on Hugging Face Spaces, providing 24/7 availability with dynamic allocation of GPU resources. The deployment architecture supports high concurrent usage while maintaining responsive performance. Feedback collection is integrated to enable model improvement through user corrections and validation.
Demonstration
Open the app and click on one of the examples for “Get Evidence from PDF” to demo the complete workflow from PDF upload through evidence retrieval to final claim verification.
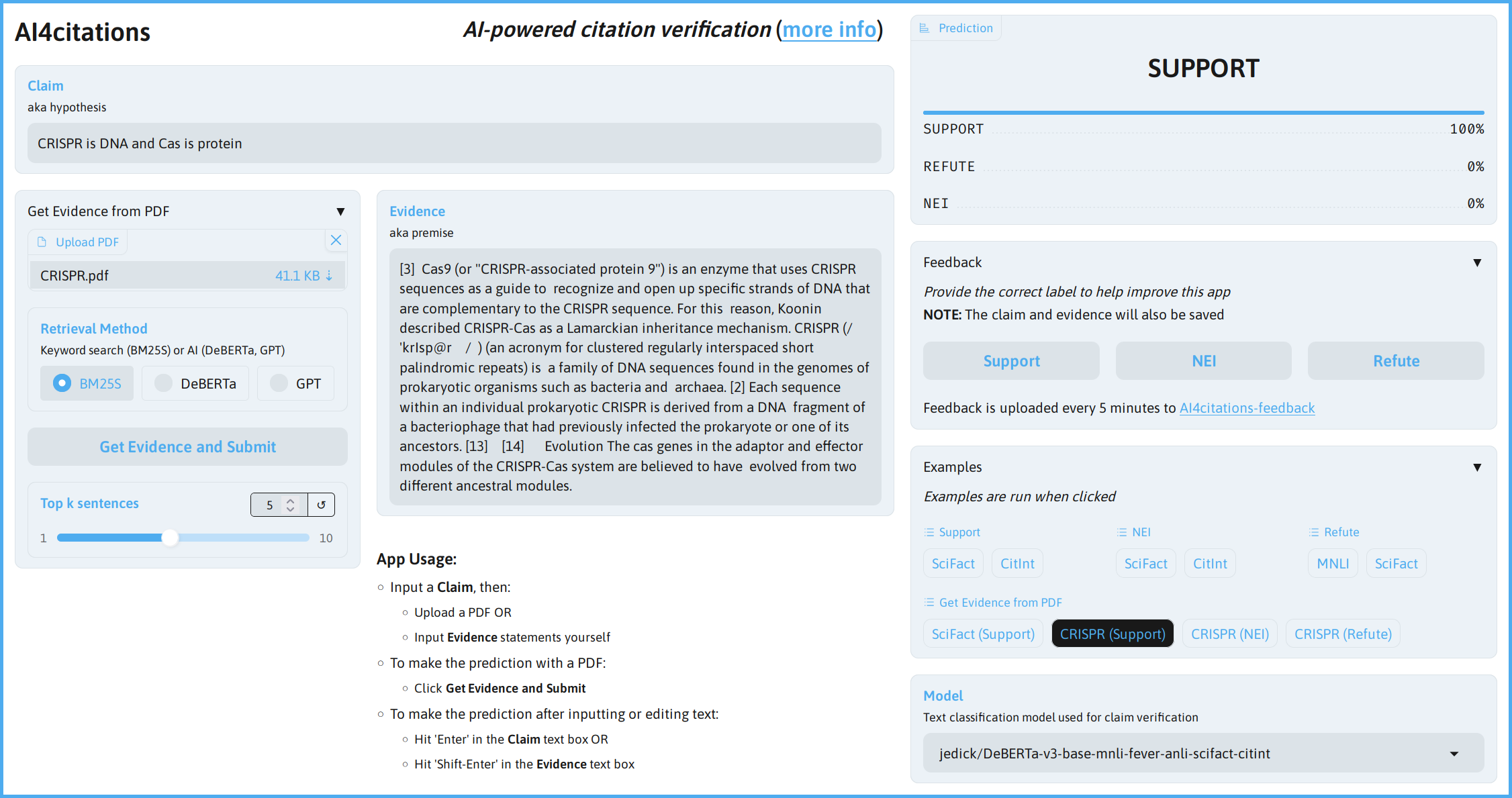
Users can experiment with different retrieval methods, compare model predictions, and provide feedback for continuous improvement. The interface provides immediate results with detailed confidence scoring and transparent methodology.
The production deployment showcases the successful transformation of a research prototype into a robust, scalable application suitable for academic researchers, journal editors, and fact-checkers requiring automated citation verification capabilities.
Try AI4citations: https://huggingface.co/spaces/jedick/AI4citations
View User Feedback: https://huggingface.co/datasets/jedick/AI4citations-feedback
Source Code: https://github.com/jedick/AI4citations